This guide is meant for users to understand the concept of Image Similarity, how can we use this capability to automate the repetitive tasks to make the data-preparation pipeline more faster, efficient, accurate & convenient .
Topics Covered
This guide covers image similarity capabilities in Labellerr:
- What is Image Similarity - Understanding the concept and measurements
- Image Similarity at Labellerr - How the feature works in our platform
- Use Cases in Data Preparation - Real-world applications and benefits
- Data Preparation Automation - How to streamline annotation workflows
- Practical Implementation - Step-by-step usage guide
Similar Images

IMAGE SIMILARITY & DATA PREPARATION
Data preparation is the process of transforming raw data so that data scientists and analysts can run it through machine learning models to uncover insights or make predictions. There are different steps in data preparation like, Data-Collection, Data-Curation & Data-Annotations. These steps are very time-consuming and requires a lots to resources and cost for doing them on scale, which can be automate or reduced by the capability of IMAGE SIMILARITY. Following is some use-cases where we can use the capability of IMAGE SIMILARITY to automate the tasks and make the process faster .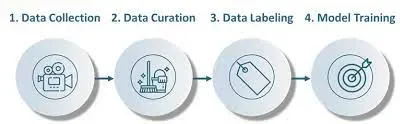
1
Data-Collection:
Data-Collection: Collecting data for training the ML model is the basic step in the machine learning pipeline. The predictions made by ML systems can only be as good as the data on which they have been trained.

Following are some of the problems that can arise in data collection:-
- Inaccurate data. The collected datasets could have some data/files that are unrelated to the problem statement. After finding one such file that is inaccurate as per the problem statement we can find out all similar files and remove them from datasets .
- Data imbalance. Some classes or categories in the data may have a disproportionately high or low number of corresponding samples. As a result, they risk being under-represented in the model. We can use the IMAGE SIMILARITY capability to find out the disproportion via finding out the similar images and then accordingly collect more data or remove data to ensure the proportion .

2
Data-Curation :
Data-Curation : Data curation is a critical part of model development as Computer Vision models are derived by learning from the data they see. We define data curation as the process of selecting, preparing and organising a collection of data such that the value of the data can be maintained over time.DUPLICATION :- When the same datasets are available at different sources, challenges such as duplication occurs. Transformation of data may alter one source leaving the other source and result in incorrect data usage. IMAGE SIMILARITY can be used to find out the similar datasets or files .
3
Data-Annotation:-
Data annotation is the process of Labelling data in various formats such as video, images, or text so that machines can understand it. So, as you now know, Image Annotation is vital in modules that involve facial recognition, computer vision, robotic vision, and more.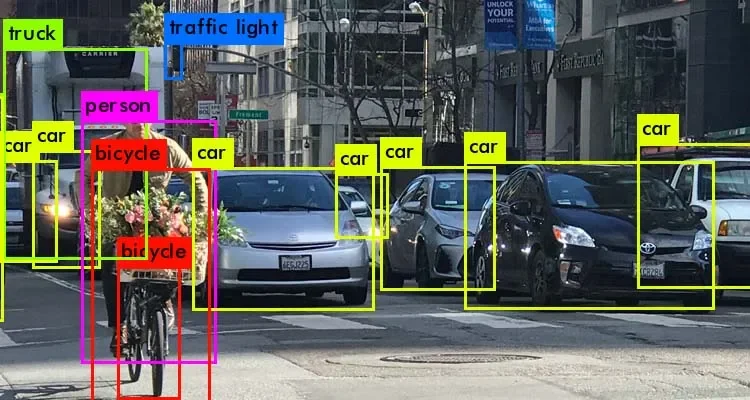
IMAGE SIMILARITY AT LABELLERR
We have used the capability of IMAGE SIMILARITY to build a feature called COPY PREVIOUS in our annotation pipeline. This feature enables a user to copy answers from the similar files in the pipeline which have been already annotated.Before going forward, please ensure that you are familiar with the Annotation Projects, Datasets and Annotation Pipelines at Labellerr. If not please visit the below links :-
Image Currently Under Annotation Process
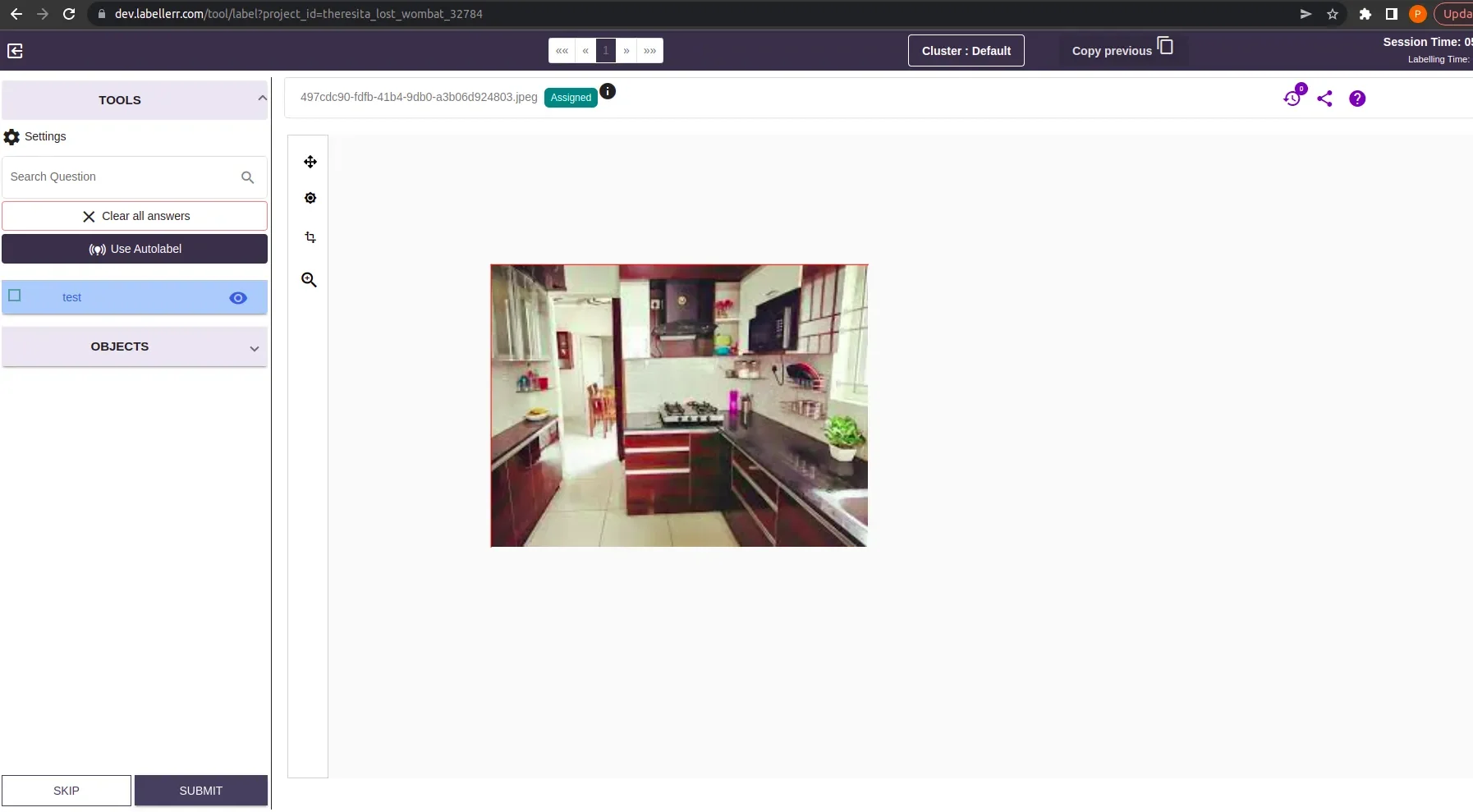
Note-1: When the “sort by” filter is set to similarity. The images are render in order of similarity. Means the First image is the most similar & Last Image is least similar image.Note-2: When the “sort by” filter is set to Recently Annotated. The images are rendered on the basis of time of annotation. Means the First image is the most recently annotated & Last Image is least recently annotated.
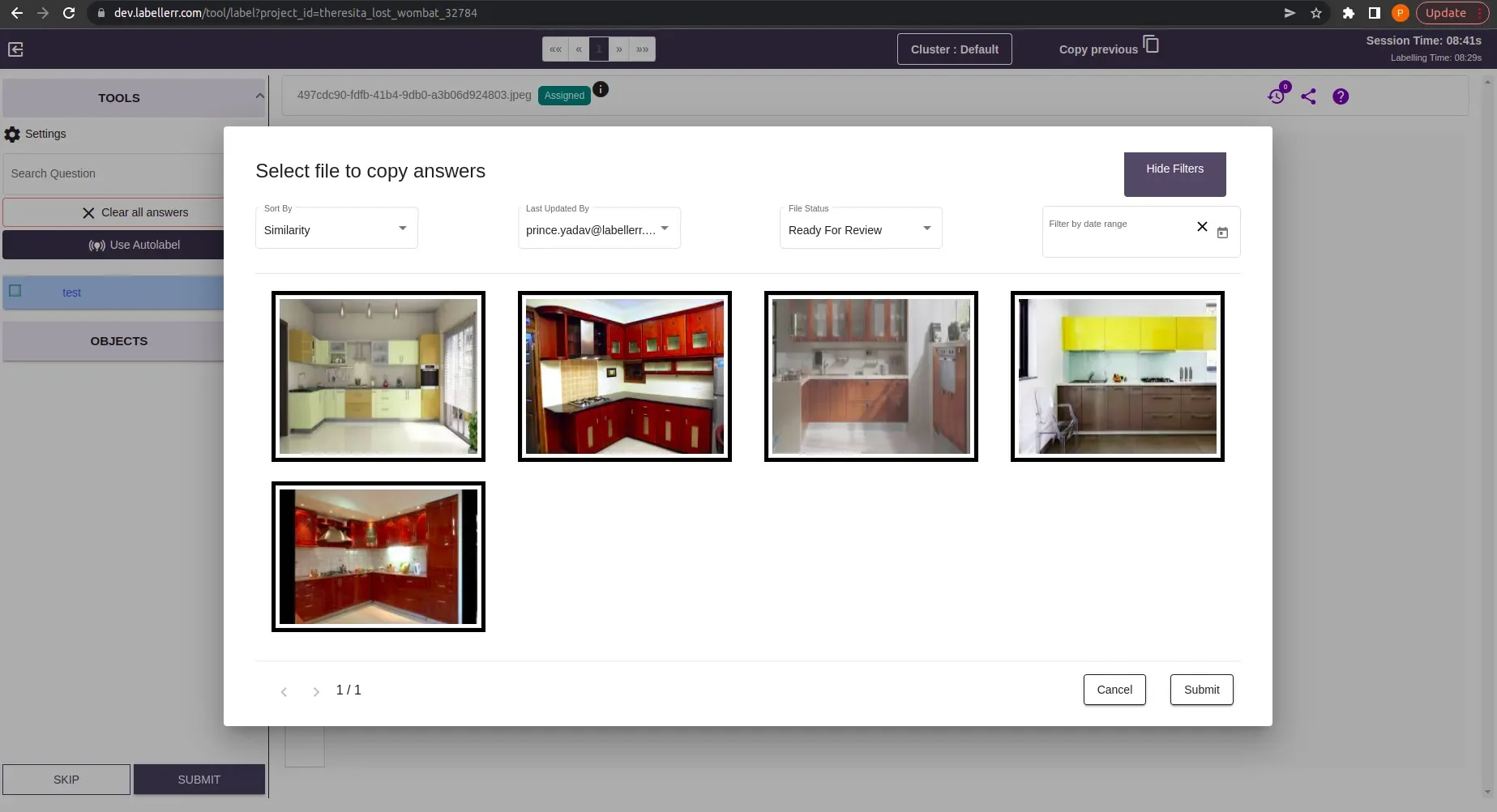
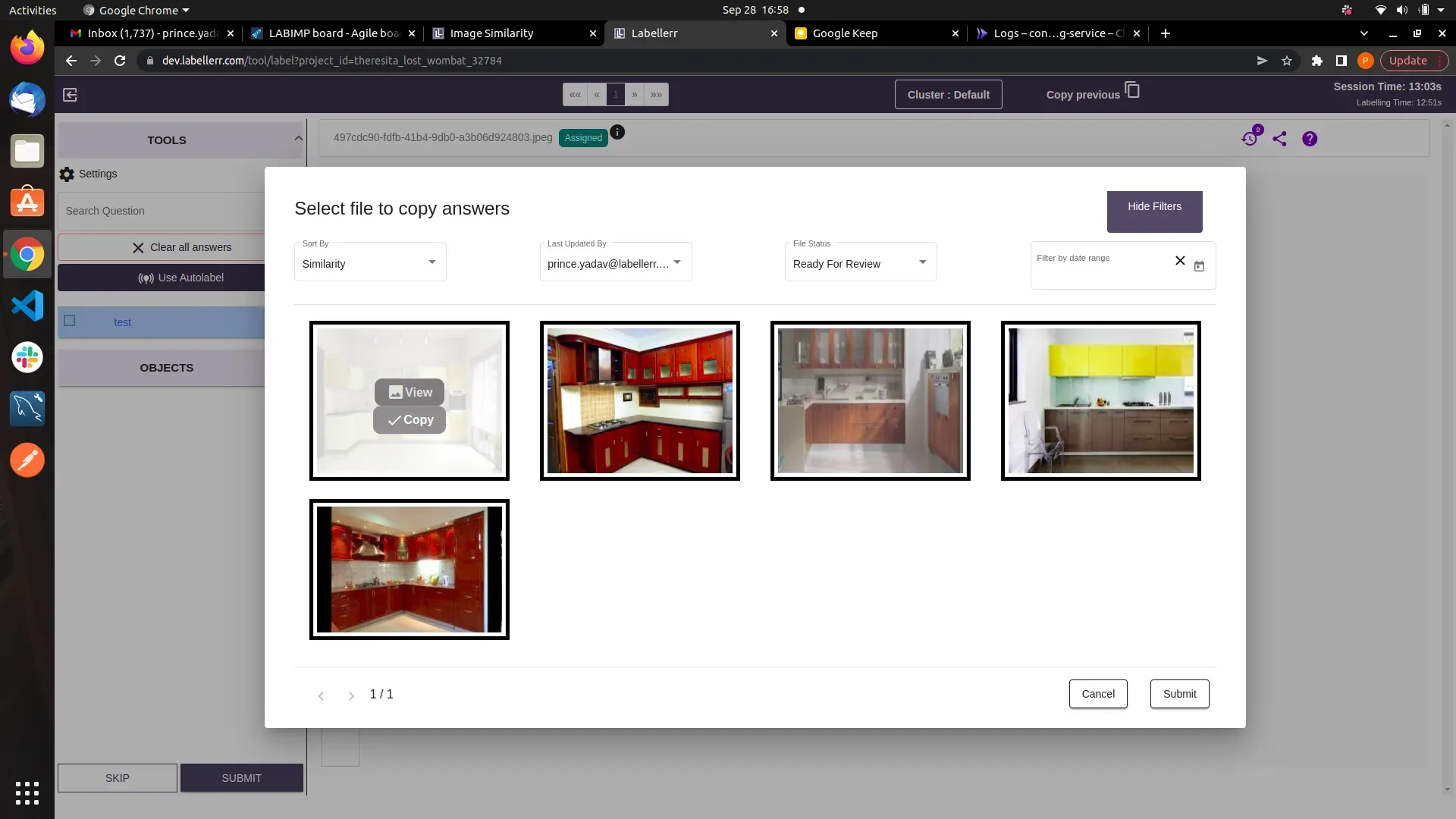
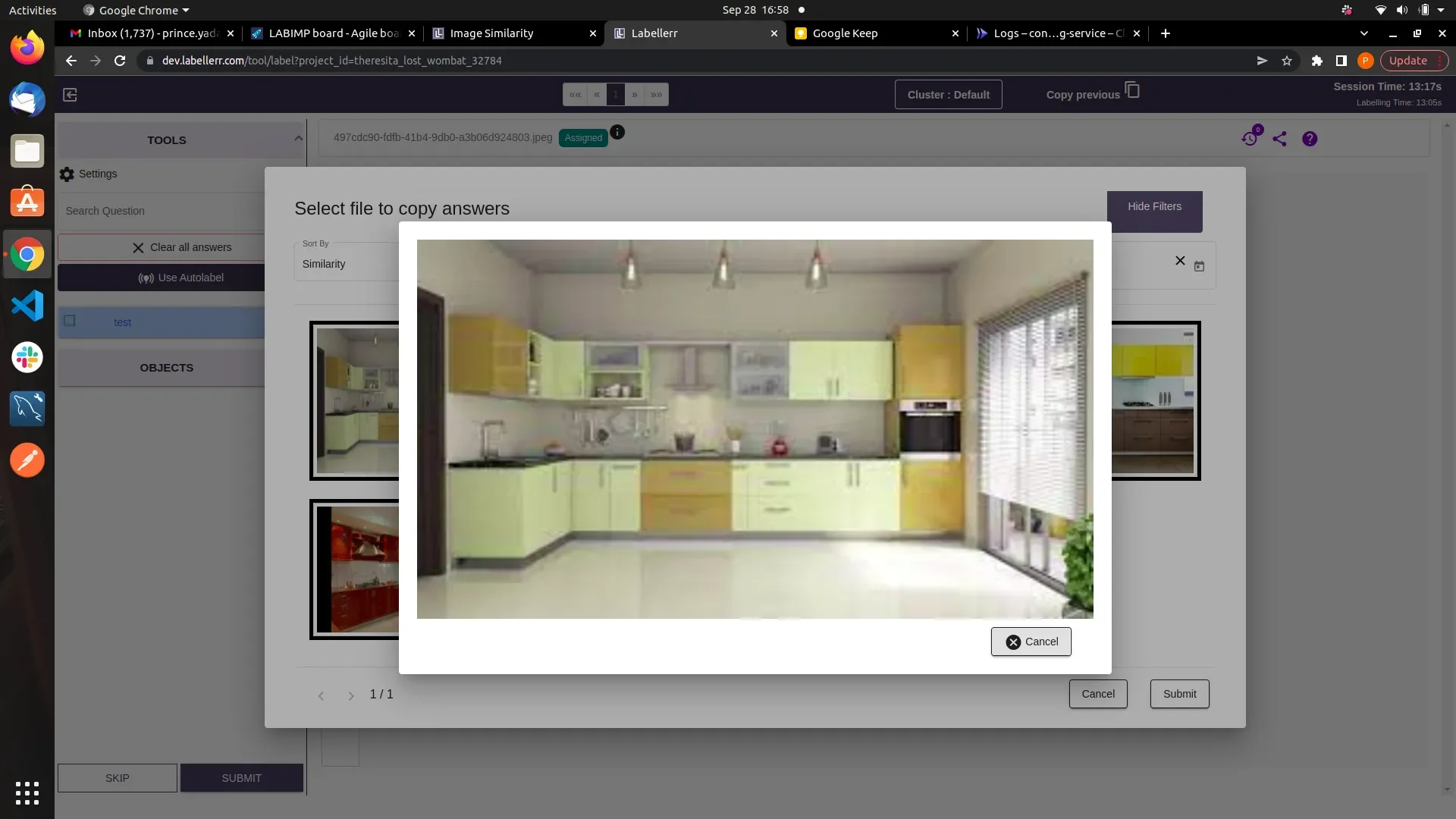
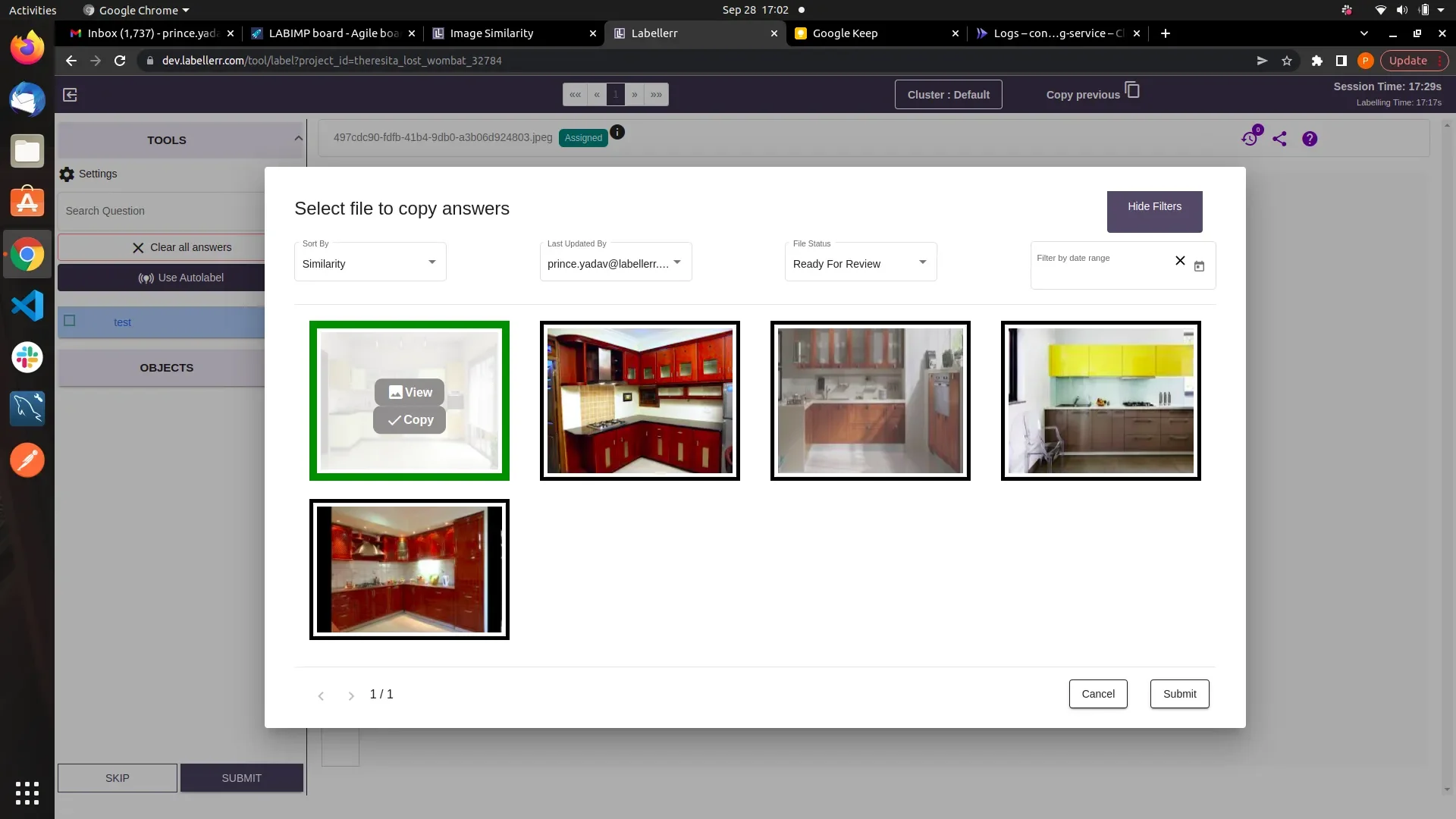
This feature can be use efficiently in annotation projects where the annotation questions are only the classification questions .
TRY IMAGE SIMILARITY AT LABELLERR
- Create a new project along with datasets. Annotate some files in the pipeline and for any specific images that feels similar to any previous image, Try out the “Copy Previous”.
- Create datasets at workspace level. Now create a new project and link the same datasets with the project. Annotate some files in the pipeline and for any specific images that feels similar to any previous image. Try out the “Copy Previous” .
- Create a project with multiple datasets. Annotate some files in the pipeline and for any specific images that feels similar to any previous image. Try out the “Copy Previous” . Observe that if the similar files are rendering from multiple datasets.
- Add more data to a existing datasets. Annotate some files in the pipeline and for any specific images that feels similar to any previous image. Try out the “Copy Previous” . Observe that if the similar files are rendering from the added files.
Note: After creating any project or linking any datasets with project, Please contact the back-end team. There is some work which is going on, till then after linking projects & datasets we need to invoke some APIs manually from back-end. This requires the project_id & datasets_id that are linked. This can be done anytime after linking project & datasets.