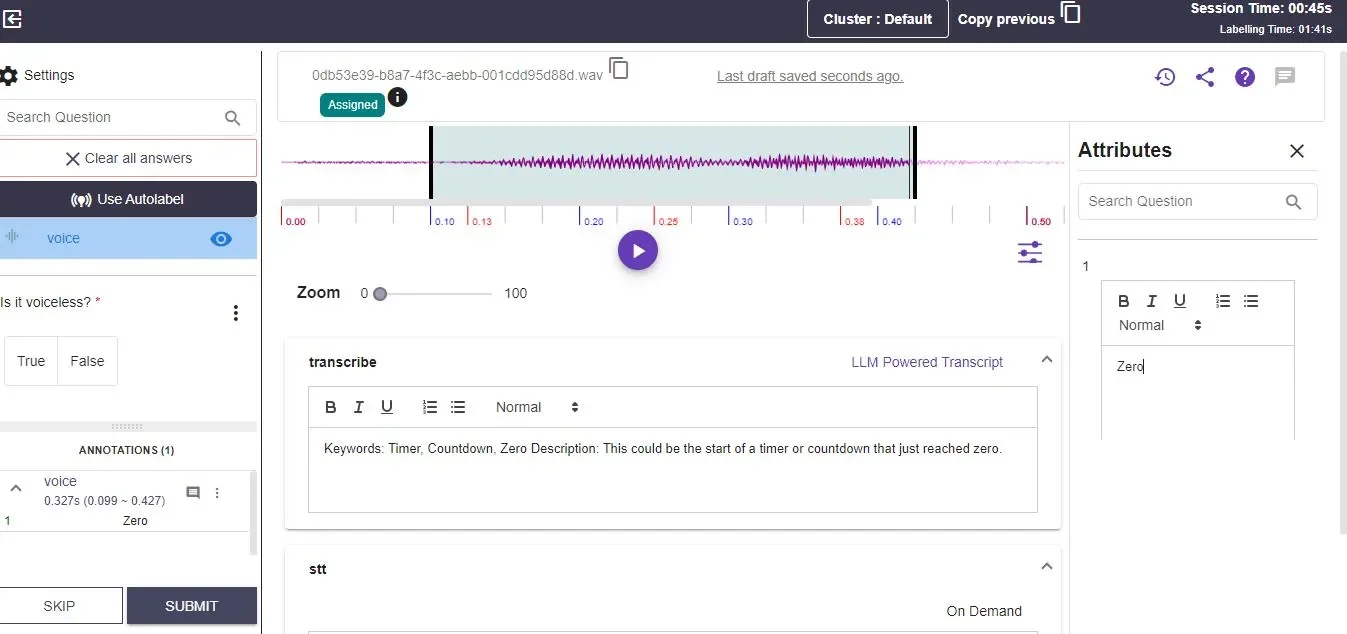
Audio segmentation divides the digital audio signal into a sequence of segments or frames and then classifies these into various classes such as speech recognition, music, or noise.
Set object type to ‘Audio segmentation’and add attributes to write the transcription in the input box.
Select the portion of the audio that needs transcription. This selection will generate a parallel attribute section on the right side.
Similarly, select objects and add transcriptions alongside the corresponding attributes in the attributes section.
Similar screens are available in the review stage, where reviewers can also edit transcriptions as needed.